
티스토리 뷰
1. EXPLAIN (ANALYZE, COSTS, VERBOSE, BUFFERS, FORMAT JSON)
조회를 하기 전에 위의 제목을 적어주면 상세한 기록이 나온다.
2. 기본 세팅
오늘은 인덱스 구현 방식과 조회를 어떻게 하느냐에 따라 성능의 극대한 차이를 보여주는 예제를 보여주도록 하겠습니다.
우선 기본 모델부터 소개
1. Issue
class Issue(models.Model):
class Meta:
indexes = [
models.Index(fields=['model_type', 'is_complete', 'id'], name='issue_type_complete_id'),
]
model_type = models.IntegerField(default=1)
is_complete = models.BooleanField(default=False)
objects = models.Manager()
class Work(models.Model):
class Meta:
indexes = [
models.Index(fields=['is_complete', 'id'], name='work_complete_id'),
models.Index(fields=['model_type', 'is_complete', 'id'], name='work_type_complete_id')
]
issue = models.ForeignKey(Issue, related_name='works', null=True, on_delete=models.CASCADE)
is_complete = models.BooleanField(default=False)
model_type = models.IntegerField(default=1)
objects = models.Manager()issue와 work는 일대다 관계를 가지고 있다.
3. Test

우선 실습하기 전에 더미 데이터로 다음과 같이 넣어주었다.
with CaptureQueriesContext(connection) as cqc:
available_issue_type_list = [2, 3, 4]
Issue.objects.filter(model_type__in=available_issue_type_list, is_complete=False).exclude(works__model_type=4).order_by('id').first()
print(cqc.captured_queries)SELECT "issue_issue"."id", "issue_issue"."model_type", "issue_issue"."is_complete"
FROM "issue_issue"
WHERE (
NOT "issue_issue"."is_complete"
AND "issue_issue"."model_type" IN (2, 3, 4)
AND NOT (
EXISTS(
SELECT (1) AS "a"
FROM "work_work" U1
WHERE (U1."model_type" = 4
AND U1."issue_id" = ("issue_issue"."id")) LIMIT 1
)
)
)
ORDER BY "issue_issue"."id" ASC LIMIT 1
with CaptureQueriesContext(connection) as cqc:
available_issue_type_list = [2, 3, 4]
exclude_issue_ids = Work.objects.filter(model_type=4).values_list('issue', flat=True)
Issue.objects.filter(model_type__in=available_issue_type_list, is_complete=False).exclude(id__in=exclude_issue_ids).order_by('id').first()
result = cqc.captured_queries
SELECT "issue_issue"."id", "issue_issue"."model_type", "issue_issue"."is_complete"
FROM "issue_issue"
WHERE
(
NOT "issue_issue"."is_complete"
AND "issue_issue"."model_type" IN (2, 3, 4)
AND NOT (
"issue_issue"."id" IN (
SELECT U0."issue_id" FROM "work_work" U0 WHERE U0."model_type" = 4
)
)
)
ORDER BY "issue_issue"."id" ASC LIMIT 1
우선 Gateher Merge가 무엇일까?
In all cases, the Gather or Gather Merge node will have exactly one child plan, which is the portion of the plan that will be executed in parallel. If the Gather or Gather Merge node is at the very top of the plan tree, then the entire query will execute in parallel.
옵티마이저가 판단하에 병행으로 처리하기 위한 작업이라고 보면 된다.
materialize는
Postgres Materialize causes poor performance in delete query
I have a DELETE query that I need to run on PostgreSQL 9.0.4. I am finding that it is performant until it hits 524,289 rows in a subselect query. For instance, at 524,288 there is no materialized...
stackoverflow.com
을 보니 메모리의 문제로 인하여 이렇게 된 것 같다.
그러면 shared_buffers를 올려볼까?
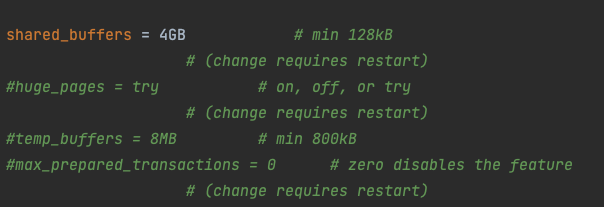

shared_buffers를 올려봤는데 큰 차이가 없다...
자세히 보니 work_mem 하고 maintenance_work_mem 을 올려주면 성능을 극대화 할 수 있다고 한다. 한 번 해봤다.
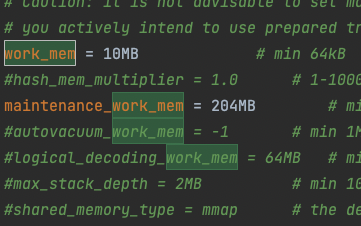
수치는 https://www.enterprisedb.com/postgres-tutorials/how-tune-postgresql-memory 의 글을 보고 따라했다.

오! 상당히 시간을 단축이 된 것을 볼 수가 있다.
그래도 첫 번째 플랜이 시간이 덜 걸린 것을 볼 수가 있다.
하지만 항상 저 상황이 더 시간이 빠를까?
이번에 각 필드에 account라는 연관관계를 추가하겠다.
이제 특정 유저에 대한 이슈에서 4번 모델 타입의 워크를 제외한 것 중 2,3,4 인 모델 타입인 이슈에 대한 것 중 아이디가 가장 작은 것을 찾을 때 어떤게 빠를 지 보자
with CaptureQueriesContext(connection) as cqc:
available_issue_type_list = [2, 3, 4]
Issue.objects.filter(
model_type__in=available_issue_type_list,
account=accounts[0],
is_complete=False
).exclude(works__model_type=4).order_by('id').first()
print(cqc.captured_queries)
"Execution Time": 10.06
with CaptureQueriesContext(connection) as cqc:
available_issue_type_list = [2, 3, 4]
exclude_issue_ids = Work.objects.filter(
model_type=4, account=accounts[0]
).values_list('issue', flat=True)
Issue.objects.filter(model_type__in=available_issue_type_list,
is_complete=False,
account=accounts[0]
).exclude(id__in=exclude_issue_ids).order_by('id').first()
result = cqc.captured_queries

"Execution Time": 5.198그렇다 이번에 2번째가 오히려 빠르다. 그 이유는 명확하다.
특정 유저에 대한 이슈가 우선 무척이나 적기 때문에 인덱스를 타면서 풀 스캔을 타지 않기 때문에 시간이 많이 걸리지 않고, 그 탐색된 결과를 제외하고 또 특정 유저에 대하여 필터링을 하기 때문에 탐색 범위가 적어져서 시간이 더 빨라진 것을 볼 수 있다.
이렇게 쿼리를 짤 때 어떻게 해야 할 지 고민해보는 것도 상당히 좋을 것 같다.
여기서 또 궁금한 것이 생겼다. 현재 보시면 제가 만든
class Meta:
indexes = [
models.Index(fields=['model_type', 'is_complete', 'id'], name='issue_type_complete_id'),
]이 인덱스를 타서 빠른 탐색이 되었는 지 한 번 확인해보는 것도 좋을 것 같아서 해볼려고 한다.
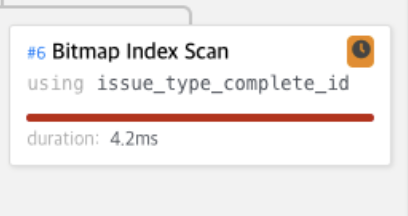
현재는 만들어서 탐색에 사용되고 있는데 이번에는 지우고 해보자

우선 인덱스를 삭제 했다.
인덱스 조회는 (https://vixxcode.tistory.com/233)
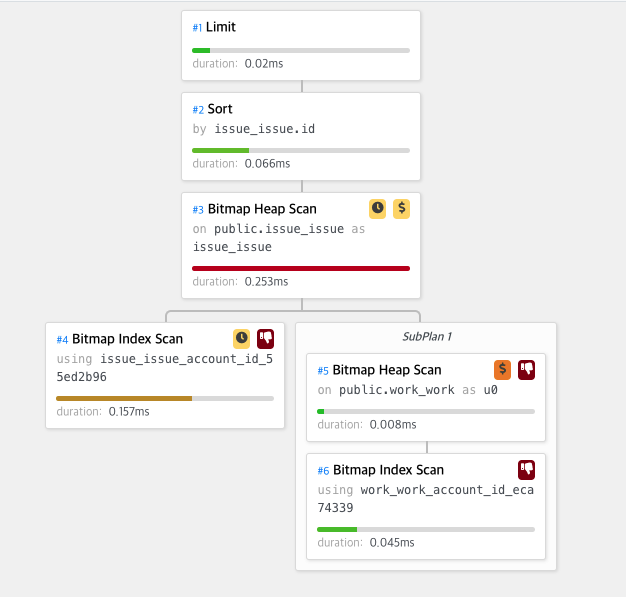
결과는 놀라웠다. 오히려 인덱스를 안 만든 것이 더 빨랐다 . 와우...
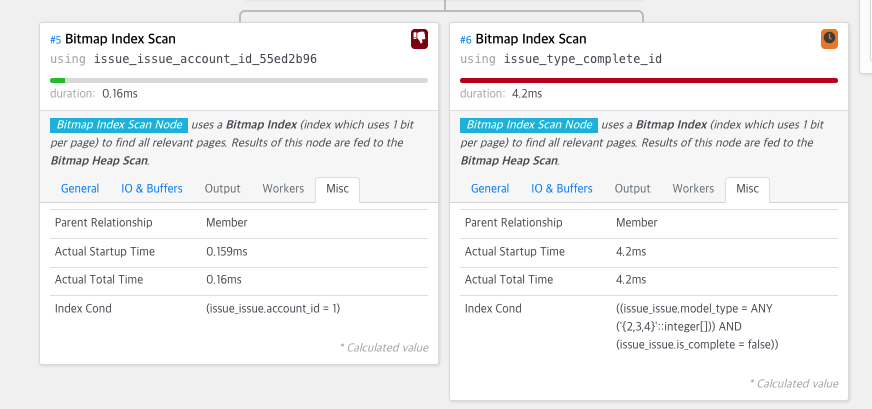
인덱스를 더 만들 때에는 아이디로 인덱스를 타고 그 다음에 다시 내가 새로 추가된 인덱스로 타면서 오히려 성능이 더 떨어지게 된 거다.

이것은 후자의 결과로서 인덱스는 아이디만 있을 때 이다.
1. 만약에 Gater Merge 또는 Materialize를 했을 때 work_mem 그리고 maintence_work_mem의 설정을 바꿔주자.
2. 인덱스를 함부로 막 추가하지 말자. 그 이유는 타지 않아도 될 인덱스를 타게 되면서 오히려 퍼포먼스를 떨어트리는 결과를 만들게 된다.
3. 이전의 결과를 토대로 바로 진행하지 말자. 조건에 따라 크게 차이날 수가 있다.
https://github.com/VIXXPARK/django-remind
GitHub - VIXXPARK/django-remind
Contribute to VIXXPARK/django-remind development by creating an account on GitHub.
github.com
'데이터베이스 > Postgresql' 카테고리의 다른 글
| [PostgreSQL] Repeatable Read, Serializable에 대해서 (2) | 2022.03.01 |
|---|---|
| [PostgreSQL] Read Committed 에 대해서 (0) | 2022.02.05 |
| [Postgresql] 세팅 값 조회 (0) | 2022.01.23 |
| [Database][Postgresql] JSONField VS JOIN 에 대한 성능 체크(jsonb vs table) (0) | 2022.01.09 |
| postgres 커멘드 라인 정리하기 (0) | 2021.07.15 |
- Total
- Today
- Yesterday
- setattr
- Celery
- 면접
- docker-compose
- Spring
- PostgreSQL
- 2021 KAKAO BLIND RECRUITMENT
- django
- Command Line
- Collections
- 백준
- DRF
- 프로그래머스
- Pattern
- 자바
- Python
- BFS
- 그래프
- docker
- 알고리즘
- 파이썬
- thread
- headers
- Linux
- dockerignore
- env
- 카카오
- postgres
- ubuntu
- Java
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |